
Что такое llms.txt и зачем он нужен
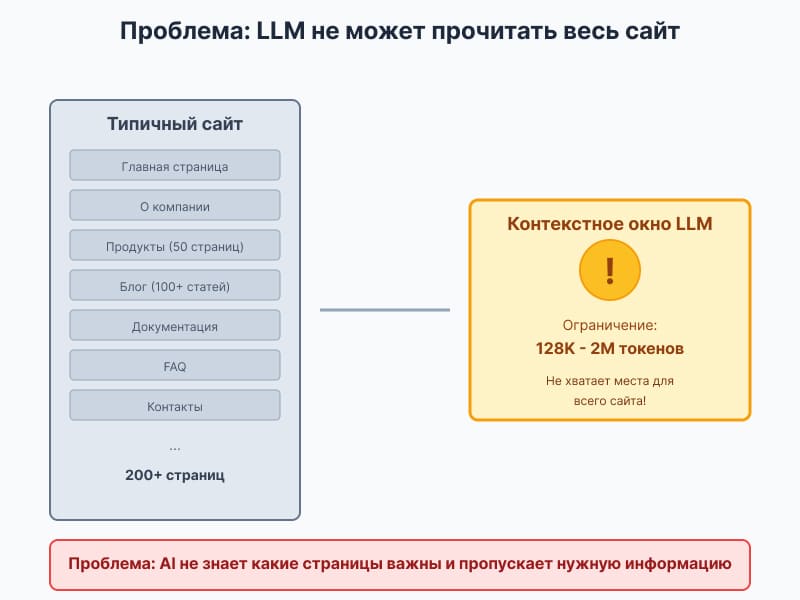
Когда пользователь спрашивает ChatGPT «какие CRM подходят для малого бизнеса» или Perplexity «как настроить Kubernetes», AI-модель ищет ответ на веб-сайтах. Но возникает проблема: типичный сайт содержит сотни страниц с HTML, навигацией, рекламой, скриптами — языковая модель физически не может прочитать всё это из-за ограничений контекстного окна.
llms.txt решает эту проблему. Это markdown-файл в корне сайта, который содержит структурированный список самых важных страниц с кратким описанием каждой. Думайте о нём как о «карте сокровищ» для AI — он показывает модели, где именно находится нужная информация, без необходимости перелопачивать весь сайт. В добавок это может весьма снизить нагрузку на ресурсы виртуального хостинга.
Пример: Вместо того чтобы парсить 200 страниц документации, AI читает llms.txt, видит «API Reference с полным описанием эндпоинтов находится здесь», переходит по ссылке и сразу получает нужную информацию.
Концепцию предложил австралийский технолог Jeremy Howard в сентябре 2024 года. С тех пор формат внедрили Anthropic, Perplexity, Hugging Face, Zapier и десятки других tech-компаний.
Кому это критически важно:
- Владельцам tech-продуктов — чтобы разработчики могли быстро найти документацию через AI
- SEO и GEO-специалистам — для видимости в ChatGPT Search, Perplexity, Claude
- Создателям контента — чтобы AI корректно цитировал ваши материалы
- Разработчикам AI-приложений — для упрощения парсинга веб-контента
🚀 Генератор llms.txt
Создайте llms.txt файл для вашего сайта за 5 минут
📝 Заполните информацию
Что такое llms.txt?
- Markdown-файл для навигации AI по сайту
- Помогает LLM находить важные страницы
- Улучшает видимость в ChatGPT, Claude, Perplexity
👁️ Превью
📌 Следующие шаги:
- Загрузите файл в корень сайта:
/llms.txt - Проверьте доступность:
yoursite.com/llms.txt - Создайте .md версии важных страниц (опционально)
- Обновляйте файл при значимых изменениях
Проблема: почему LLM не могут эффективно читать обычные сайты
Языковые модели сталкиваются с тремя фундаментальными проблемами при работе с веб-контентом:
Ограничение контекстного окна
Современные LLM обрабатывают от 128 тысяч до 2 миллионов токенов за раз. Звучит внушительно, но типичный корпоративный сайт с документацией содержит эквивалент нескольких миллионов токенов.
Конкретный пример: Документация React занимает около 500 страниц. Если AI попытается прочитать всё сразу, это займёт больше половины контекстного окна — и места для самого вопроса пользователя почти не останется.
Результат: AI приходится выбирать, какие страницы читать, и часто выбор случаен или основан на устаревших принципах SEO-ранжирования.
HTML — это кошмар для парсинга
Веб-страница в HTML включает:
- Навигационное меню (повторяется на каждой странице)
- Футер с юридической информацией
- Скрипты аналитики и рекламы
- CSS-классы и атрибуты
- Всплывающие окна подписки
- Комментарии и отзывы
Измеримая проблема: На типичной странице блога полезного текста 20-30%, остальное — технический мусор для AI. Модель тратит дорогие токены на обработку
вместо содержательного контента.
 Отсутствие приоритизации
Отсутствие приоритизации
У сайта нет способа сказать AI: «Вот эти 5 страниц критически важны для понимания продукта, остальные 200 — второстепенные».
Для AI все страницы равноценны. Модель может прочитать устаревший пост в блоге 2019 года вместо актуальной документации 2024 года, просто потому что старая страница имеет больше обратных ссылок.
Что происходит на практике:
- Пользователь: «Как работает API Stripe?»
- AI читает главную страницу (маркетинг), страницу с ценами, блог-пост о новой фиче
- AI пропускает страницу «API Quick Start», потому что не знал о её существовании
- Результат: неполный или неточный ответ
llms.txt решает все три проблемы одновременно: сжимает информацию до самого важного, убирает HTML-шум, явно указывает приоритеты.
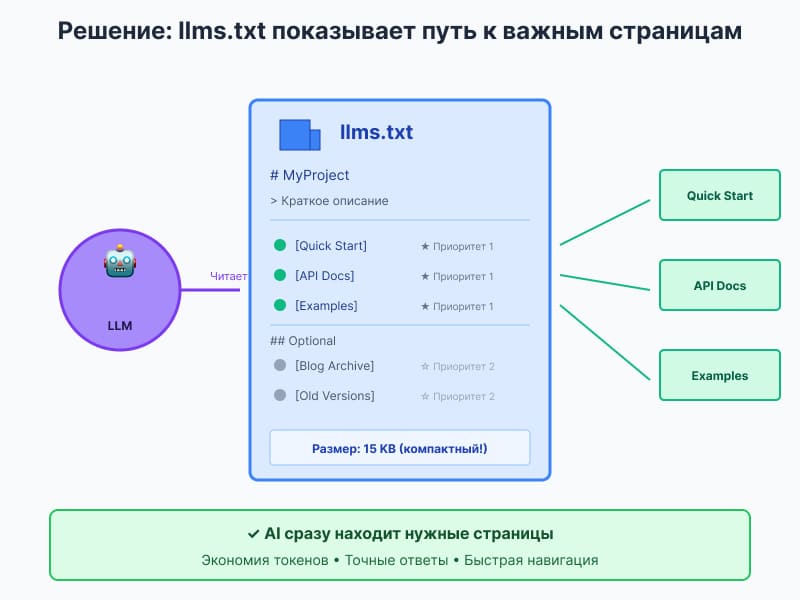
Как работает llms.txt
llms.txt — это markdown-файл, расположенный по адресу https://yoursite.com/llms.txt. Он содержит структурированный список важных страниц вашего сайта с краткими описаниями.
Базовая структура файла
Спецификация llms.txt определяет чёткий формат:
# Название проекта > Краткое описание в одном предложении Дополнительная информация о проекте в нескольких абзацах. Контекст, который поможет AI понять, как интерпретировать остальной контент. ## Основные ресурсы - [Название страницы](URL): Краткое описание содержимого - [API Reference](URL): Полная документация всех эндпоинтов - [Quick Start Guide](URL): Пошаговое руководство для начала работы ## Примеры - [Todo App Example](URL): Полноценное приложение с объяснениями - [Code Snippets](URL): Готовые фрагменты кода для типичных задач ## Optional - [Advanced Topics](URL): Углублённые материалы для экспертов - [Changelog](URL): История изменений версий
Ключевые элементы формата:
- H1 заголовок (обязательно) — название проекта или сайта
- Blockquote (рекомендуется) — одно предложение с сутью проекта
- Описательные абзацы (опционально) — дополнительный контекст
- H2 секции — тематические разделы со списками ссылок
- Списки ссылок — формат
Название: Описание - Секция «Optional» — вторичная информация, которую можно пропустить
 Расширенная версия: .md файлы для каждой страницы
Расширенная версия: .md файлы для каждой страницы
Спецификация рекомендует создавать markdown-версии важных страниц. Если у вас есть страница docs/api-guide.html, создайте также docs/api-guide.html.md с чистым markdown-содержимым этой страницы.
Почему это важно: AI может читать markdown в 10 раз быстрее, чем парсить HTML. Модель получает чистый текст без необходимости разбираться в структуре HTML.
Вариант с полным контентом: llms-full.txt
Некоторые сайты создают llms-full.txt — файл, содержащий весь текстовый контент сайта в одном документе. Это «сплющенная» (flattened) версия всего сайта.
Пример: llms-full.txt для документации Anthropic Claude весит ~966 KB и содержит 115,378 слов — это весь контент сайта docs.anthropic.com в одном файле.
Преимущества:
- AI получает полный контекст за одно обращение
- Нет необходимости делать множество HTTP-запросов
- Идеально для анализа всего сайта разом
Недостатки:
- Большой размер может превысить контекстное окно некоторых моделей
- Требует регулярного обновления при изменении контента
Технические детали
Расположение: Обязательно /llms.txt в корне домена. Опционально можно создавать файлы в подпапках /docs/llms.txt, /blog/llms.txt.
MIME-тип: text/plain или text/markdown
Кодировка: UTF-8
Размер: Рекомендуется 10-50 KB для основного файла. Для llms-full.txt может быть до нескольких мегабайт.
Обновление: При значительных изменениях структуры сайта или контента.
Пример из реального проекта: FastHTML
FastHTML — один из первых проектов, полностью внедривших спецификацию:
# FastHTML > FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's FT "FastTags" into a library for creating server-rendered hypermedia applications. Important notes: - Although parts of its API are inspired by FastAPI, it is NOT compatible with FastAPI syntax - FastHTML is compatible with JS-native web components and vanilla JS library, but not with React, Vue, or Svelte ## Docs - [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features - [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes, CSS classes, headers ## Examples - [Todo list application](https://github.com/AnswerDotAI/fasthtml/blob/main/examples/adv_app.py): Detailed walk-thru of a complete CRUD app showing idiomatic patterns ## Optional - [Starlette full documentation](https://gist.githubusercontent.com/.../starlette-sml.md): A subset of Starlette docs useful for FastHTML development
Что здесь сделано правильно:
- Сразу понятно, что это за библиотека (blockquote)
- Указаны критичные ограничения (не совместима с FastAPI/React)
- Логическая группировка: документация, примеры, дополнительное
- Каждая ссылка имеет краткое описание
- Секция Optional для неприоритетного контента
Как создать llms.txt для своего сайта
Шаг 1: Определите цель файла
Спросите себя: для чего пользователи обращаются к AI с вопросами о моём сайте?
Для tech-документации:
- «Как установить библиотеку X?»
- «Какие методы доступны в API?»
- «Покажи пример использования функции Y»
Для бизнес-сайта:
- «Чем занимается компания X?»
- «Сколько стоит продукт Y?»
- «Есть ли у компании API?»
Для медиа/блога:
- «Что пишет блог X про тему Y?»
- «Какие статьи есть по теме Z?»
Цель определяет, какие страницы включить в llms.txt.
Шаг 2: Составьте список критичных страниц
Откройте Google Analytics или аналогичный инструмент. Отфильтруйте:
Приоритет 1 — Топ-10 страниц по трафику
Это страницы, которые уже приносят ценность пользователям.
Приоритет 2 — Страницы с высоким временем на сайте
Если пользователи проводят здесь 3+ минуты, значит контент полезен и детален.
Приоритет 3 — Входные точки для органического трафика
Страницы, на которые пользователи попадают из поиска — они решают конкретные проблемы.
Для технических продуктов обязательно включите:
- Getting Started / Quick Start
- API Reference
- Installation Guide
- Примеры кода
- FAQ или Troubleshooting
Для контентных сайтов включите:
- 5-10 самых популярных статей
- Категории или тематические разделы
- О проекте / О команде
Не включайте:
- Служебные страницы (Privacy Policy, Terms of Service)
- Страницы с устаревшей информацией
- Страницы с дублирующимся контентом
- Внутренние инструменты или админ-панели
Шаг 3: Напишите описания для каждой ссылки
Каждая ссылка должна иметь описание на 5-15 слов, объясняющее, что именно на этой странице.
Плохо:
- [Documentation](https://example.com/docs): Documentation
Хорошо:
- [API Reference](https://example.com/docs/api): Complete list of all endpoints with parameters and response examples
Плохо:
- [Blog](https://example.com/blog): Our blog
Хорошо:
- [Technical Blog](https://example.com/blog): In-depth articles about React performance, state management, and optimization techniques
Описание должно помочь AI понять, нужна ли эта страница для ответа на вопрос пользователя.
Шаг 4: Создайте файл
Используйте шаблон из спецификации:
# [Название вашего проекта] > [Одно предложение: что это и для кого] [1-2 абзаца дополнительного контекста, если нужно] ## [Секция 1: например, "Documentation"] - [Страница 1](URL): Описание - [Страница 2](URL): Описание ## [Секция 2: например, "Examples"] - [Пример 1](URL): Описание ## Optional - [Дополнительная страница](URL): Описание
Сохраните как llms.txt (без расширения .md).
Шаг 5: Разместите и проверьте
Размещение:
- Загрузите файл в корневую директорию сайта
- Убедитесь, что он доступен по адресу
https://yoursite.com/llms.txt
Проверка доступности:
curl https://yoursite.com/llms.txt
Должен вернуть содержимое файла с HTTP статусом 200.
Проверка валидности:
Используйте llms.txt Validator для проверки соответствия спецификации.
Проверка в браузере:
Откройте yoursite.com/llms.txt — должен отобразиться читаемый текст без HTML-разметки.
Шаг 6: Создайте .md версии страниц (опционально, но рекомендуется)
Для каждой важной страницы создайте markdown-версию:
Если есть https://yoursite.com/docs/api-guide.html, создайте также https://yoursite.com/docs/api-guide.html.md с чистым markdown-содержимым.
Как получить markdown:
- Используйте инструменты типа Markdowner или Pandoc
- Для WordPress есть плагины экспорта в markdown
- Для статических сайтов можно использовать исходные .md файлы
Шаг 7: Обновляйте регулярно
Добавьте в календарь напоминание проверять llms.txt:
- После запуска новых фич или продуктов
- При значительных изменениях документации
- Минимум раз в квартал
Что проверять:
- Все ссылки работают (нет 404)
- Описания актуальны
- Нет устаревших страниц в списке
- Добавлены новые важные разделы
Реальные примеры llms.txt
Anthropic (Claude Documentation)
docs.anthropic.com/llms-full.txt
Anthropic создали llms-full.txt, содержащий документацию Claude API в виде «сплющенного» текста. Это полный контент docs.anthropic.com без HTML, навигации и других элементов.
Что они сделали:
- Весь контент доступен за одно обращение — не нужно делать десятки HTTP-запросов
- Чистый текст без разметки — модель тратит токены только на содержание
Perplexity (собственная документация)
docs.perplexity.ai/llms-full.txt
Perplexity, будучи AI-поисковиком, сами внедрили llms.txt для своей документации. AI-поисковик создаёт файл, чтобы другие AI могли лучше понять, как он работает.
Hugging Face
huggingface-projects-docs-llms-txt.hf.space/accelerate/llms.txt
Hugging Face создали llms.txt для документации библиотеки Accelerate. Они используют базовую версию с ссылками вместо полного текста.
Zapier
Zapier использует llms-full.txt для документации по интеграциям и API. Файл содержит описание интеграций, инструкции по настройке и примеры.
FastHTML (пример из официальной спецификации)
FastHTML — один из первых проектов, полностью внедривших спецификацию. Их файл включён как образец в официальной документации llmstxt.org:
# FastHTML > FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's FT "FastTags" into a library for creating server-rendered hypermedia applications. Important notes: - Although parts of its API are inspired by FastAPI, it is NOT compatible with FastAPI syntax - FastHTML is compatible with JS-native web components and vanilla JS library, but not with React, Vue, or Svelte ## Docs - [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features - [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes, CSS classes, headers ## Examples - [Todo list application](https://github.com/AnswerDotAI/fasthtml/blob/main/examples/adv_app.py): Detailed walk-thru of a complete CRUD app showing idiomatic patterns ## Optional - [Starlette full documentation](https://gist.githubusercontent.com/.../starlette-sml.md): A subset of Starlette docs useful for FastHTML development
Что здесь сделано правильно:
- Сразу понятно, что это за библиотека (blockquote)
- Указаны критичные ограничения (не совместима с FastAPI/React)
- Логическая группировка: документация, примеры, дополнительное
- Каждая ссылка имеет краткое описание
- Секция Optional для неприоритетного контента
LLMsTxt Manager
Сервис для управления llms.txt файлами сам использует llms.txt для описания своих функций и инструкций.
Инструменты для создания llms.txt
Создать llms.txt можно вручную, но для больших сайтов удобнее использовать автоматизированные инструменты.
Онлайн-генераторы
- Вводите URL сайта
- Выбираете страницы для включения
- Генерирует готовый markdown
- Бесплатно для небольших сайтов
Hostinger llms.txt Validator
Проверяет корректность созданного файла и соответствие спецификации.
Плагины для CMS
WordPress: Website LLMs.txt
Автоматически создаёт llms.txt для WordPress-сайтов:
- Выбираете: посты, страницы или всё вместе
- Плагин генерирует файл автоматически
- Обновляется при публикации нового контента
- Более 3000 скачиваний за первые 3 месяца
Hostinger Plugin (для managed WordPress)
Встроенный инструмент в панели Hostinger:
- Включается одним переключателем
- Автоматическая генерация при публикации сайта
- Валидация встроена
Инструменты для разработчиков
Open-source инструмент для конвертации сайта в markdown:
- Парсит HTML и создаёт чистый markdown
- Создаёт структуру для llms.txt
- Бесплатный, можно модифицировать под свои нужды
CLI-инструмент для обработки llms.txt:
- Читает llms.txt и создаёт развёрнутые версии
- Генерирует llms-ctx.txt и llms-ctx-full.txt
- Полезен для создания контекстных файлов для LLM
Один из первых инструментов для создания llms.txt:
- Краулит сайт
- Извлекает контент
- Генерирует markdown-версии страниц
Автоматизированный генератор от Jakub Kopecky:
- Crawling сайта с настройками глубины
- Генерация как базового, так и full-версии
- Интеграция с Apify платформой
Библиотеки для интеграции
JavaScript: llmstxt-js
Для интеграции в JS-приложения
PHP: llms-txt-php
Библиотека для чтения и записи llms.txt в PHP-проектах
Python: llms_txt2ctx module
Модуль для парсинга и обработки llms.txt файлов
Плагины для генераторов документации
VitePress Plugin
Автоматически генерирует llms.txt для VitePress-сайтов:
- Интеграция в build process
- Автоматическое обновление при изменении документации
Docusaurus Plugin
Плагин для Docusaurus, следующий стандарту llms.txt:
- Генерация при сборке сайта
- Настройка приоритетов страниц
nbdev (для Python-проектов)
Все проекты на nbdev теперь автоматически создают .md версии страниц:
- FastCore, FastHTML и другие проекты Answer.AI используют это
- Markdown-версии генерируются из Jupyter notebooks
Drupal LLM Support
Recipe для Drupal 10.3+:
- Полная поддержка спецификации llms.txt
- Автоматическая генерация для Drupal-сайтов
- Настройка через админ-панель
Что выбрать?
Для быстрого старта: Wordlift Generator — вводите URL, получаете файл за минуты
Для WordPress: Плагин Website LLMs.txt — устанавливаете, настраиваете, забываете
Для крупных проектов: Markdowner или FireCrawl — больше контроля над процессом
Для документации: VitePress/Docusaurus плагины — автоматизация в build pipeline
Для custom решений: Используйте библиотеки (JS, PHP, Python) и пишите свой генератор
Важное предупреждение о безопасности
Любой инструмент, который краулит ваш сайт, должен быть проверен на безопасность:
- Используйте только инструменты с открытым кодом или от известных компаний
- Проверяйте сгенерированный файл перед загрузкой
- Убедитесь, что инструмент не собирает ваши данные
- Для корпоративных сайтов лучше генерировать llms.txt вручную или самописным скриптом
Best practices и рекомендации
Пишите описания для AI, а не для людей
AI читает иначе, чем люди. Человек сканирует глазами, AI обрабатывает последовательно слово за словом.
Плохое описание (для людей):
- [Documentation](URL): Check out our docs!
Хорошее описание (для AI):
- [API Documentation](URL): Complete reference for all REST endpoints including authentication, rate limits, and request/response examples
Принцип: Каждое описание должно отвечать на вопрос «Что конкретно я найду на этой странице?»
Используйте конкретные термины
AI лучше работает с специфичными терминами, чем с общими фразами.
Избегайте:
- «our platform»
- «solutions»
- «innovative approach»
- «learn more»
Используйте:
- «REST API with JSON responses»
- «React components library»
- «PostgreSQL schema migration guide»
- «Installation steps for Ubuntu 22.04»
Структурируйте по частоте использования
Самые часто запрашиваемые страницы должны быть в начале файла, в первых секциях.
Для tech-документации правильный порядок:
- Quick Start / Getting Started
- Installation / Setup
- Core Concepts
- API Reference
- Advanced Topics (в секции Optional)
- Changelog (в секции Optional)
Для бизнес-сайтов:
- О продукте / услуге
- Pricing
- Кейсы / примеры
- Контакты
- О компании (в Optional)
- Вакансии (в Optional)
Оптимизируйте размер файла
Базовый llms.txt: 10-50 KB
Только ссылки с описаниями. Идеально для сайтов с хорошо структурированным контентом.
llms-full.txt: 100 KB — 2 MB
Полный текст критичных страниц. Подходит для документации, где важен полный контекст.
Когда использовать какой:
- До 50 страниц → базовый llms.txt
- 50-200 страниц → llms.txt + выборочные .md версии
- 200+ страниц → llms.txt + llms-full.txt для ключевых разделов
Правило секции «Optional»
Всё, что в секции Optional, может быть пропущено AI при нехватке контекстного окна. Туда идёт:
- История компании
- Changelog и архивы версий
- Подробная информация о команде
- Дополнительные материалы, не критичные для понимания продукта
Не помещайте в Optional:
- Актуальные цены
- Текущую документацию API
- Инструкции по установке
- Контактную информацию
Тестируйте с реальными запросами
После создания llms.txt протестируйте его с AI:
Тест 1: Базовое понимание
Спросите ChatGPT или Claude: «Что такое [ваш продукт] и для кого он?»
Проверьте, упоминается ли ваш llms.txt и корректна ли информация.
Тест 2: Технические детали
«Как установить [ваш продукт]?» или «Покажи пример использования [вашего API]»
AI должен найти соответствующую страницу из llms.txt.
Тест 3: Сравнение
«Чем [ваш продукт] отличается от [конкурент]?»
Проверьте, использует ли AI информацию из вашего llms.txt.
Избегайте дублирования robots.txt директив
llms.txt — это НЕ расширение robots.txt. Не добавляйте туда:
# НЕПРАВИЛЬНО - не делайте так Disallow: /admin Disallow: /private User-agent: GPTBot
Для контроля доступа используйте robots.txt или meta-теги.
Поддерживайте актуальность
Обновляйте при:
- Запуске новой версии продукта
- Изменении API (новые эндпоинты, deprecation)
- Изменении цен
- Редизайне сайта с изменением URL
- Публикации критично важного контента
Не обновляйте при:
- Небольших правках текста на существующих страницах
- Публикации обычных blog posts (если они не в топ-10)
- Косметических изменениях дизайна
Версионирование (для tech-продуктов)
Если у вас несколько версий продукта с разной документацией:
# MyAPI > RESTful API for data processing ## Current Version (v2.0) - [v2.0 Documentation](URL): Latest stable version - [Migration Guide v1 → v2](URL): Breaking changes and migration steps ## Previous Versions - [v1.5 Documentation](URL): Legacy version, supported until Dec 2025 ## Optional - [v1.0 Archive](URL): Deprecated, no longer supported
Мультиязычность
Если у вас сайт на нескольких языках:
Вариант 1: Отдельные файлы
/llms.txt(английский, по умолчанию)/llms-ru.txt(русский)/llms-es.txt(испанский)
Вариант 2: Поддомены
en.yoursite.com/llms.txtru.yoursite.com/llms.txt
Вариант 3: Папки
/en/llms.txt/ru/llms.txt
Выбирайте вариант, соответствующий структуре вашего сайта.
Влияние на SEO и видимость в AI-поисковиках (GEO)
 Что такое GEO и почему это важно
Что такое GEO и почему это важно
GEO (Generative Engine Optimization) — это оптимизация контента для AI-поисковиков и языковых моделей. Это не замена SEO, а дополнение.
Статистика: По данным Statista 2024, к 2028 году 36 миллионов взрослых американцев будут использовать AI для поиска информации — это в два раза больше, чем в 2024.
Ключевое отличие от SEO:
- SEO оптимизирует для ранжирования в Google/Яндекс
- GEO оптимизирует для упоминания в ответах ChatGPT/Claude/Perplexity
llms.txt — это НЕ фактор ранжирования в Google
Важно понимать: llms.txt не влияет на позиции в традиционных поисковиках.
Google, Яндекс, Bing продолжают использовать свои алгоритмы, основанные на:
- Обратных ссылках
- Качестве контента
- Поведенческих факторах
- Технических факторах (скорость загрузки, мобильная версия)
llms.txt никак не учитывается в этих алгоритмах.
Аналогия: llms.txt для AI-поисковиков — это как Schema.org разметка для rich snippets. Не влияет на позиции, но улучшает представление в результатах.
Как llms.txt работает с AI-поисковиками
ChatGPT Search (OpenAI)
С октября 2024 ChatGPT имеет функцию веб-поиска. Когда модель обращается к сайту для проверки информации:
- Читает llms.txt (если есть)
- Получает структурированный список важных страниц
- Переходит на конкретную страницу вместо парсинга всего сайта
Perplexity
Perplexity строит ответы в реальном времени, цитируя источники. llms.txt помогает быстро найти релевантную страницу и корректно процитировать информацию.
Claude (Anthropic)
При использовании инструмента поиска Claude обращается к llms.txt для быстрого понимания структуры сайта.
Google AI Overviews / Gemini
Google тестирует AI-обзоры (AI Overviews) в результатах поиска. Хотя официально не подтверждено, структурированная информация из llms.txt может помочь Gemini лучше понять контент сайта.
Метрики для отслеживания
1. Упоминания в AI-ответах
Как измерять:
- Составьте список из 10-15 типичных вопросов в вашей нише
- Раз в месяц задавайте эти вопросы ChatGPT, Claude, Perplexity
- Отслеживайте, упоминается ли ваш сайт и как часто
- Фиксируйте корректность цитирования
2. Увеличение «бренд-запросов» в Google
Косвенный эффект: пользователи узнают о компании через AI-ответ, затем ищут её напрямую в Google.
Метрика: Отслеживайте branded search в Google Search Console — рост запросов с названием компании/продукта.
3. Реферальный трафик из AI-инструментов
Некоторые AI-поисковики передают referrer при клике на ссылку.
Настройка в Google Analytics:
Создайте сегмент с источниками:
chat.openai.comperplexity.aiclaude.ai- Или параметры URL типа
?ref=ai-search
Сравнение с существующими стандартами
llms.txt vs robots.txt
| Аспект | robots.txt | llms.txt |
|---|---|---|
| Цель | Управление доступом краулеров | Навигация для LLM |
| Формат | Директивы (Allow/Disallow) | Markdown с описаниями |
| Для кого | Поисковые боты | AI-модели |
| Обязателен? | Нет, но рекомендуется | Нет, но полезен |
Эти файлы дополняют друг друга, не заменяют.
llms.txt vs sitemap.xml
| Аспект | sitemap.xml | llms.txt |
|---|---|---|
| Содержание | Все страницы сайта | Кураторский список важных страниц |
| Формат | XML | Markdown |
| Описания | Нет или минимальные | Детальные описания каждой страницы |
| Размер | Может быть огромным | Компактный (10-50KB обычно) |
Sitemap говорит «у меня 500 страниц», llms.txt говорит «вот 10 самых важных с объяснением, что на них».
llms.txt vs Schema.org
| Аспект | Schema.org | llms.txt |
|---|---|---|
| Расположение | Внутри HTML-страниц | Отдельный файл |
| Формат | JSON-LD или Microdata | Markdown |
| Цель | Структурированные данные для поисковиков | Навигация для LLM |
| Читаемость | Машинная | Человеческая и машинная |
Schema.org структурирует данные (товары, статьи, события), llms.txt структурирует навигацию по этим данным.
Идеальная комбинация:
- robots.txt — контроль доступа
- sitemap.xml — полный список страниц
- Schema.org — структурированные данные на страницах
- llms.txt — навигация для AI
Позиция индустрии: мнения экспертов
Скептическая точка зрения (Brett Tabke, WebmasterWorld):
«Мы не должны думать, что LLM отличаются от обычных поисковых роботов. Граница между ‘поисковиком’ и ‘LLM’ почти стёрта. Google — это поисковик с прикрученным LLM, ChatGPT — это LLM с прикрученным поиском. Со временем Google интегрирует LLM напрямую в код поисковика, и различие исчезнет. llms.txt просто затемняет этот факт. XML sitemaps и robots.txt уже выполняют эту функцию.»
Прагматичная точка зрения (David Ogletree, маркетолог):
«Я не хочу, чтобы люди продолжали думать, что есть разница между LLM и Google. Для меня они одно и то же и должны обрабатываться одинаково.»
Сторонники внедрения:
«В мире с почти нулевыми научными стандартами для GEO, llms.txt — это первый шаг к созданию чего-то измеримого и воспроизводимого. Когда Google говорит ‘создавайте качественный контент’, это искусство. Когда мы говорим ‘разместите llms.txt’, это наука.»
Практические рекомендации
1. Внедряйте llms.txt, но не отказывайтесь от SEO
llms.txt — это дополнение, не замена. Продолжайте работать над:
- Качеством контента
- Обратными ссылками
- Технической оптимизацией
- Поведенческими факторами
2. Фокусируйтесь на «full» версии для документации
Если у вас tech-продукт с документацией, llms-full.txt с полным текстом даст больше пользы, чем просто список ссылок.
3. Мониторьте результаты, но будьте реалистичны
Не ожидайте мгновенного взрывного роста трафика. Эффект накопительный и проявляется в течение 3-6 месяцев.
4. Используйте llms.txt для собственного анализа
Даже если AI-поисковики не используют ваш файл, «сплющенная» версия сайта полезна для:
- Анализа ключевых слов
- Поиска дублирующегося контента
- Оценки общего объёма контента
- Экспорта для обработки другими инструментами
Преимущества внедрения llms.txt
Для владельцев сайтов и контента
1. Контроль над представлением в AI
Вы сами выбираете, какие страницы AI увидит первыми. Это критично для компаний с большим количеством контента.
Проблема без llms.txt: AI может прочитать устаревший blog post и дать информацию о продукте, который вы уже не поддерживаете.
Решение с llms.txt: Вы явно указываете «вот текущая документация v2.0, а v1.0 в секции Optional».
2. Экономия ресурсов сервера
Вместо того чтобы AI краулил сотни страниц, он читает один файл llms.txt и переходит только на релевантные страницы. Это снижает нагрузку на сервер от AI-ботов.
3. Точность цитирования
AI получает структурированную информацию с контекстом, что снижает вероятность ошибок и неточностей в ответах пользователям. Когда вы даёте прямую ссылку на актуальную страницу с ценами, AI не будет цитировать старые данные из забытого поста.
4. Конкурентное преимущество на ранней стадии
llms.txt находится на ранней стадии адопции. Компании, внедрившие стандарт сейчас, получают преимущество в видимости в AI-ответах, пока конкуренты только изучают тему.
5. Аналитические возможности
llms-full.txt можно использовать для внутреннего анализа:
- Полнотекстовый поиск по всему сайту
- Анализ ключевых слов и тем
- Поиск дублирующегося контента
- Экспорт для обработки AI-инструментами
Для пользователей AI-поисковиков
1. Более точные ответы
LLM получает структурированную, актуальную информацию напрямую от источника, а не парсит HTML наугад.
2. Актуальная информация
Владельцы сайтов обновляют llms.txt при значимых изменениях, что снижает риск получения устаревших данных.
3. Правильные ссылки для углубления
AI не только отвечает на вопрос, но и даёт корректные ссылки на детальную информацию из llms.txt.
Для разработчиков AI-приложений
1. Стандартизированный формат
Вместо написания кастомных парсеров для HTML каждого сайта, вы просто читаете markdown.
Код для парсинга llms.txt:
import requests
import markdown
response = requests.get('https://example.com/llms.txt')
content = response.text
# Markdown легко парсится любой библиотекой
parsed = markdown.markdown(content)
Против парсинга HTML с BeautifulSoup, регулярками и эвристиками для каждого сайта.
2. Надёжность
llms.txt — это стабильный файл, который меняется редко и предсказуемо. HTML сайта может меняться при каждом релизе, ломая ваш парсер.
3. Экономия ресурсов
Один HTTP-запрос к llms.txt против десятков запросов для краулинга сайта. Чистый markdown занимает меньше токенов LLM, чем HTML с разметкой.
4. Меньше rate limiting
Сайты менее склонны блокировать бота, который делает 1-2 запроса (llms.txt + нужная страница), чем бота, который краулит 50 страниц подряд.
Для SEO и маркетинговых команд
1. Новый канал трафика
AI-поисковики — это растущий источник трафика. llms.txt помогает в нём присутствовать.
2. Контроль messaging
Вы определяете, как AI описывает ваш продукт пользователям. Это brand management для эпохи AI.
3. Легкость внедрения
Создание llms.txt занимает от 30 минут до нескольких часов. Это минимальные инвестиции с потенциально значительным эффектом.
4. Интеграция в существующий workflow
llms.txt не требует переделки сайта. Создали файл, разместили — готово. Обновления минимальны.
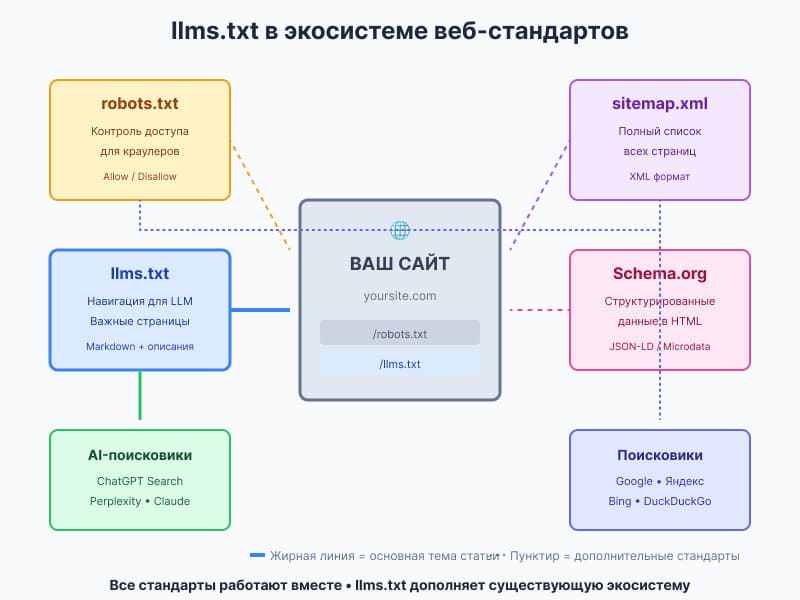
Интеграция с существующими веб-стандартами
llms.txt создан для сосуществования с текущими веб-стандартами, а не для их замены.
Совместная работа стандартов
Идеальная экосистема для сайта:
yourdomain.com/ ├── robots.txt # Контроль доступа для всех ботов ├── sitemap.xml # Полный список страниц для поисковиков ├── llms.txt # Навигация для AI └── index.html # + Schema.org разметка внутри
Каждый файл выполняет свою функцию:
robots.txt — привратник
- «Googlebot, ты можешь заходить сюда, но не туда»
- «GPTBot, тебе нельзя в /admin»
sitemap.xml — карта местности
- «У меня 500 страниц, вот их список»
- «Эти страницы обновлялись на прошлой неделе»
llms.txt — экскурсовод
- «Вот 10 самых важных мест с объяснениями»
- «Начни отсюда, если ищешь информацию о X»
Schema.org — этикетки на экспонатах
- «Это товар, вот его цена и рейтинг»
- «Это статья, вот её автор и дата»
Когда использовать каждый инструмент
Используйте robots.txt когда:
- Нужно заблокировать индексацию технических страниц
- Хотите контролировать доступ разных ботов к разным разделам
- Есть страницы, которые не должны попадать в поиск
Используйте sitemap.xml когда:
- У вас большой сайт (50+ страниц)
- Хотите ускорить индексацию новых страниц
- Нужно указать поисковикам на все важные страницы
Используйте Schema.org когда:
- Продаёте товары (нужны rich snippets)
- Публикуете статьи (хотите красивые сниппеты в Google)
- Есть события, рецепты, вакансии (для специальных карточек)
Используйте llms.txt когда:
- Хотите присутствовать в AI-ответах
- У вас техническая документация
- Важна правильная презентация в ChatGPT/Claude/Perplexity
Практический пример комплексного подхода
Сайт tech-документации:
- robots.txt
User-agent: * Allow: /docs/ Disallow: /admin/ Disallow: /api/private/ Sitemap: https://example.com/sitemap.xml
- sitemap.xml
https://example.com/docs/
2025-01-15
1.0
- llms.txt
# MyAPI Documentation > REST API for payment processing ## Getting Started - [Quick Start](URL): Complete setup in 5 minutes - [Authentication](URL): API keys and OAuth flow ## API Reference - [Endpoints](URL): All available endpoints with examples
- Schema.org в HTML страниц
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "Quick Start Guide",
"author": "MyAPI Team"
}
Результат:
- Google индексирует все страницы (sitemap.xml)
- Rich snippets в результатах поиска (Schema.org)
- Админка защищена от индексации (robots.txt)
- AI получает структурированную навигацию (llms.txt)
Рекомендации по приоритетам
Минимальный набор (для любого сайта):
- robots.txt
- sitemap.xml
Стандартный набор (для бизнес-сайтов):
- robots.txt
- sitemap.xml
- Schema.org на ключевых страницах
- llms.txt
Полный набор (для tech-продуктов и документации):
- robots.txt с детальным контролем доступа
- sitemap.xml с приоритетами
- Schema.org на всех типах контента
- llms.txt с markdown-версиями страниц
- llms-full.txt для полного контекста
Перспективы развития стандарта
Текущее состояние адопции
Факты внедрения (по данным из источников):
- Более 3000 установок WordPress-плагина Website LLMs.txt за первые 3 месяца после запуска
- Крупные tech-компании используют стандарт: Anthropic, Perplexity, Hugging Face, Zapier
- Все проекты на платформе nbdev (Answer.AI, fast.ai) автоматически создают .md версии страниц
Вывод: Стандарт находится на ранней стадии адопции, но уже получил признание в tech-сообществе.
Возможная стандартизация
llms.txt пока не имеет официального статуса (нет RFC, нет одобрения W3C), но развивается как community-driven стандарт.
Что может произойти:
Сценарий 1: Официальная стандартизация
Если адопция достигнет критической массы (5-10% сайтов), возможно:
- Создание RFC для формализации спецификации
- Поддержка крупными платформами (WordPress core, CMS)
- Включение в web standards
Сценарий 2: Интеграция в существующие стандарты
llms.txt может стать частью расширенной спецификации sitemap.xml или отдельной секцией robots.txt.
Сценарий 3: Эволюция в более сложный формат
Возможно появление структурированных метаданных:
--- version: 1.0 language: en last_updated: 2025-01-15 content_type: documentation --- # Project Name ...
Автоматизация и инструменты
Что появится в ближайшие 1-2 года:
1. Встроенная генерация в CMS
- WordPress, Drupal, Joomla будут генерировать llms.txt автоматически
- Настройка через админ-панель: какие разделы включать
- Автообновление при публикации нового контента
2. Интеграция в CI/CD для документации
- Docusaurus, VitePress, MkDocs автоматически создают llms.txt при сборке
- GitHub Actions для валидации llms.txt при коммитах
- Автоматическое тестирование: работают ли все ссылки
3. AI-инструменты для оптимизации
- Анализаторы, которые оценивают качество llms.txt
- Рекомендации: «Добавьте описание для ссылки X»
- A/B тестирование разных версий llms.txt
4. Мониторинг и аналитика
- Дэшборды с метриками: сколько AI обращаются к вашему llms.txt
- Отслеживание упоминаний в AI-ответах
- ROI калькуляторы для GEO
Интеграция с AI-агентами
Самый перспективный сценарий — использование llms.txt AI-агентами для автоматизации задач.
Пример будущего использования:
Пользователь даёт задачу AI-агенту: «Изучи документацию Stripe API и создай интеграцию с нашим приложением».
Агент:
- Читает llms.txt Stripe
- Находит ссылку на API Reference и Quick Start
- Читает markdown-версии этих страниц
- Изучает примеры кода
- Создаёт интеграцию
Без llms.txt агенту пришлось бы краулить десятки страниц, тратить время на парсинг HTML, и рисковать пропустить важную информацию.
Возможные расширения стандарта
1. Версионирование API документации
# MyAPI ## Current Version (v2.0) - [v2.0 Docs](URL) ## Deprecated - [v1.0 Docs](URL): End of life: Dec 2025
2. Поддержка мультимедиа
## Video Tutorials - [Installation Walkthrough](URL): 5-minute video guide
3. Интерактивные элементы
## Try It - [API Playground](URL): Test endpoints in browser - [Code Sandbox](URL): Live examples
4. Метаданные о лицензировании
--- content_license: CC-BY-4.0 allow_training: false ---
Это может помочь создателям контента контролировать использование для обучения моделей.
Влияние на будущее контента
llms.txt — это симптом более глубокого сдвига: контент создаётся не только для людей, но и для машин.
Что это означает для создателей контента:
1. Структура важнее стиля
Красивый дизайн не виден AI. Логическая структура с чёткими заголовками и списками — видна отлично.
2. Markdown как основной формат
Всё больше контента изначально создаётся в markdown, который легко конвертируется и в HTML для людей, и в чистый текст для AI.
3. Метаданные становятся критичными
Даты публикации, авторы, версии продукта — эта информация помогает AI понять актуальность и релевантность.
4. Контент как база знаний
Сайты превращаются в структурированные базы знаний, где каждая страница — это атомарная единица информации с чёткой темой.
Риски и вызовы
1. Спам и злоупотребления
Как и с keywords stuffing в прошлом, возможны попытки манипулировать llms.txt:
- Нерелевантные ключевые слова
- Ссылки на чужие сайты
- Дезинформация
Решение: AI-платформы будут валидировать соответствие llms.txt реальному контенту сайта.
2. Конфиденциальность
llms.txt по сути карта вашего сайта. Конкуренты могут использовать её для анализа.
Решение: Включайте только публичную информацию. Конфиденциальное — в приватные разделы.
3. Поддержка актуальности
Устаревший llms.txt хуже, чем его отсутствие — AI даст неверную информацию.
Решение: Автоматизация обновлений через CMS или CI/CD.
4. Фрагментация стандарта
Разные платформы могут интерпретировать формат по-своему.
Решение: Сообщество должно придерживаться базовой спецификации с llmstxt.org.
Заключение
llms.txt — это не временный тренд, а логичная адаптация веба к эпохе, где AI становится основным способом поиска информации для миллионов пользователей.
Ключевые выводы:
- llms.txt решает реальную проблему — помогает LLM эффективно навигировать по сайтам с ограниченным контекстным окном
- Это не замена SEO — это дополнение, фокусирующееся на новом канале трафика через AI-поисковики
- Внедрение простое — от 30 минут до нескольких часов для создания базовой версии
- Польза есть даже без массовой адопции — llms-full.txt полезен для собственного анализа сайта
- Ранние адоптеры получают преимущество — пока менее 1% сайтов используют стандарт
Практические шаги:
- Начните сейчас — создайте базовую версию llms.txt за час
- Тестируйте — проверьте, как AI-поисковики отвечают на вопросы о вашей нише
- Итерируйте — обновляйте файл на основе результатов
- Мониторьте — отслеживайте упоминания в AI-ответах и реферальный трафик
- Масштабируйте — после успеха с одним сайтом, внедряйте на других проектах
Для кого это критично прямо сейчас:
- Tech-компании с документацией
- SaaS-продукты
- Образовательные платформы
- Медиа и блоги с экспертным контентом
- E-commerce с детальными гайдами по продуктам
Для кого можно подождать:
- Небольшие локальные бизнесы без онлайн-присутствия
- Сайты-визитки на 3-5 страниц
- Проекты, где AI-трафик не релевантен
Мир поиска меняется. Google остаётся важным, но ChatGPT, Perplexity и Claude создают новую реальность. llms.txt — это ваш способ быть видимым в этой новой реальности.
Начните сегодня. Пока конкуренты думают, вы можете стать первым в вашей нише, кто правильно представлен в ответах AI-поисковиков.
Полезные ресурсы:
- Официальная спецификация
- llms.txt Hub — каталог сайтов с llms.txt
- Validator — проверка корректности файла
- GitHub Repository — обсуждение стандарта
- Discord сообщество — обмен опытом